Word count works well, but suffers from bias due to long documents (more words), and also from rewarding lots of boring words (the, it, a, is, to ...).
Let's see how well it all worked.
Finding Interesting / Boring Words Automatically
If we apply the measure to the recipes data set, we should be able to identify the boring (stop) words automatically. These will be the ones with the lowest relevance scores.Previously, the most frequent words for a recipes corpus was full of boring words. The first interesting word "oil" appeared at position 13, after 12 boring words ranked higher! Here they are again for easy reference:
the 273
and 203
a 133
with 79
for 77
in 72
1 58
to 56
of 49
2 44
then 43
until 41
oil 41
Relevance scores for a word are per-document. But we can sum them up across all documents. Here's what the words with the top 10 look like (shown with their relevance scores)
[('sauce', 0.072479554515290895),
('them', 0.070833510080924769),
('little', 0.062832341904529035),
('rice', 0.058276255134080412),
('butter', 0.057278834991103734),
('bread', 0.055933326383546908),
('they', 0.054793552703163897),
('quantity', 0.051914014707442335),
('together', 0.050062707525060902),
('grated', 0.048860949578921925),
('broth', 0.048693197257887351),
('tomato', 0.048444379129175236),
('boiled', 0.047588072543957513),
('flour', 0.047404394383271695),
('water', 0.046392876975336547),
('then', 0.046343005577901039),
('pepper', 0.044368328433798621),
('some', 0.044303584017951085),
('very', 0.043970962688707774),
('that', 0.043831469829911401)]
Much much better! That top 20 contains lots of interesting words with only a few we would consider not so interesting. There are no short boring stop-words like "a", "in", "to" .. so our measure which penalises shorter words works well!
Let's see what the bottom 20 look like ... these should be the boring words:
[('and', 0.0),
('in', 0.0),
('the', 0.0),
('up', 0.0012725563329122366),
('i', 0.0012816579235383377),
('bit', 0.0017987306071704534),
('had', 0.0017987306071704534),
('now', 0.0017987306071704534),
('1', 0.0020042948378737836),
('3', 0.0020042948378737836),
('4', 0.0020042948378737836),
('2', 0.0020042948378737836),
('32', 0.0020148808604443747),
('leaf', 0.0022240465989832267),
('your', 0.0022240465989832267),
('wet', 0.0022988261123030452),
('top', 0.0022988261123030452),
('pie', 0.0022988261123030452),
('than', 0.0024192873309550364),
('line', 0.0024192873309550364)]
Yup - these are all boring .. except maybe leaf.
For a method that didn't rely on manually providing a list of stop words, this approach works really well. And it'll adapt to different corpuses, as each will have different word usage.
Here's a word cloud based on these relevance scores.

Compare that with our previous best word cloud:
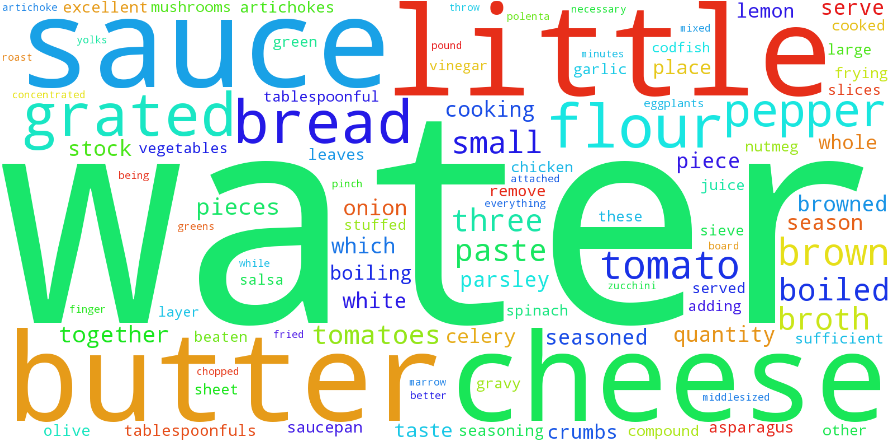
What we're seeing is two different pictures - the first tries to show words that are interesting per-document, the second shows words that are prominent across the corpus. Both of these approaches are useful when exploring text.
Notebook on Github
All the code is on github. The notebook for this pipeline is at:Challenging Texts
Some text corpora are more challenging than others. The word clouds for the Iraq War Chilcot Report and the Clinton Emails data sets have not been that illuminating ... because they'e filled up with words that appear often but aren't that interesting. Here's a reminder of what they looked like before:

Let's see how our attempt at reducing the impact of boring words works. Remember, this means reducing the impact of words that appear often but in all documents, making them less "unique".

You can see that the Iraq Report word cloud has new and interesting insights - multinational, resolution, basra, baghdad, de-ba'athification, map, inspectors, intelligence, did witness, weapons, ... much more insightful than the more expected words we had before. Interestingly, the words iraq, report and inquiry are in the bottom 20 for relevance (interestingness).
Let's try the Clinton emails which were really very challenging because the emails are fairly informal, lack continuity or strucure, and full of un-polished prose.

Well, we can see that we no longer have boring words like state and department, unclassified and date, subject and sent. You'll recognise these as words you find in the raw text of all emails - they're not that illuminating .. so our relevance measure really works to penalise them. Great!
What else does that word cloud show - well it brings forward key dates, 2009, 08-31-2015 and 06-30-2015. If you were investigating the emails, these would be worth looking into. As it happens, these are the dates the emails were released, so not that interesting for us .. but they could have been.
Identities pop out too. Abedin is a close advisor and aide to Clinton - you can read about here: http://www.vanityfair.com/news/2016/01/huma-abedin-hillary-clinton-adviser. Cheryl and Mills are the same person, Cheryl Mills, another aide: http://www.politico.com/story/2015/09/cheryl-mills-hillary-clinton-aide-213242. The same for Jacob Sullivan https://en.wikipedia.org/wiki/Jake_Sullivan
A few key email addresses also pop out .. including hrod17@clintonemail.com and hdr22@clintonemail.com ... apparently secret email accounts she is alleged to have used inappropriately for official business: http://www.factcheck.org/2015/05/clintons-secret-email-accounts/
Search Relevance
Let's see how search result ranking changes with this relevance measure. The following shows the results of searching for the word "king" in Shakespeare's Macbeth.Searching the basic word count index gives:
macbeth_act_01_scene_02.txt 14.0
macbeth_act_01_scene_04.txt 7.0
macbeth_act_01_scene_03.txt 6.0
macbeth_act_01_scene_06.txt 5.0
macbeth_act_04_scene_03.txt 4.0
macbeth_act_05_scene_08.txt 3.0
macbeth_act_03_scene_01.txt 3.0
macbeth_act_01_scene_05.txt 3.0
macbeth_act_04_scene_01.txt 2.0
macbeth_act_03_scene_06.txt 2.0
macbeth_act_02_scene_03.txt 2.0
macbeth_act_03_scene_02.txt 1.0Searching the relevance index gives:
macbeth_act_01_scene_02.txt 0.010196
macbeth_act_01_scene_06.txt 0.006776
macbeth_act_01_scene_04.txt 0.005312
macbeth_act_01_scene_03.txt 0.001888
macbeth_act_01_scene_05.txt 0.001810
macbeth_act_03_scene_06.txt 0.001803
macbeth_act_05_scene_08.txt 0.001636
macbeth_act_03_scene_01.txt 0.000935
macbeth_act_03_scene_02.txt 0.000807
macbeth_act_04_scene_03.txt 0.000759
macbeth_act_04_scene_01.txt 0.000627
macbeth_act_02_scene_03.txt 0.000605Both ways of sorting the search results give is Act 1 Scene 2 as the first result. If we have a look at the actual text, we can see why .. it is a key scene with King Duncan.
But the second place result is different. The relevance index places Act 1 Scene 6 second, whereas the basic word count give sis Act 1 Scene 4. Both involve the king, but scene 6 is shorter and is mostly about the king's arrival speech, so is less "diluted".
The fact that very similar documents appear in the top, albeit in a different, order suggests we're not wilding off with the new relevance measure.
Summary
Basic word count is a good way of working out what a text is about. Given it's extreme simplicity, it's power is pretty amazing.But where it falls down, we can use a refined measure - we call it relevance - which counters the bias of longer documents, penalises short words, and promotes the uniqueness of a word too.
We should use both measures as part of our toolkit, as this relevance measure can diminish words which really are relevant but happen to be prevalent in the text corpus.
No comments:
Post a Comment