Most of our work has looked at words on their own. We know that meaning is often in the context of a word, so we must look around any single word to try to capture this contextual meaning.
There are several ways of doing that - some of them fairy sophisticated. But for now, we'll start super simple, as usual, and grow from there, ready for the more complex stuff later.
Co-Occurrence: Words That Occur After A Word
Let's start by considering which words occur after a given word. So for example, if I thought about the word "apple", maybe the word "pie" is most likely to occur after this. If I think about the word "Iraq" maybe the word "war" is most likely to appear next.We kinda looked at this when we broke a corpus into 2-grams and counted how often they occurred. We're going to do the same sort of counting again but a bit differently because we want to later build on the approach we develop here. It will become clear why we're doing it differently, I promise!
Let's jump into the (not very deep) deep end! Have a look at the following table.

Let's decode what this is. You can see down the left words like "apple", "pie" and "fish". These have been labelled word1. That was easy enough.
You can also see across the top a similar thing, words labelled word2. What the numbers in the table are showing is how likely the second word2 is right after word1 in a given corpus. Fair enough.
What are the numbers inside the table? Those are the likelihoods that word1 is followed by word2. The illustrated example is "apple" followed by "pie" ... as in "apple pie" ... which has a likelihood of 0.99 out of a maximum of 1.0. That's very high - which means that apple is very likely to be followed by pie. Makes sense again ...
Often such matrices are symmetric - but that's not the case here. The word "pie" is not likely to be followed by the word "apple", and it shows in the table as a low likelihood of 0.05. It's not zero because our text cleaning might strip punctuation and so the word apple might actually be the beginning of a new sentence of sub-phrase. Again this all makes sense .. apple pie .. not pie apple.
The actual numbers used here are probabilities between 0 and 1. We could have chosen another kind of measure, like word count, which is simpler. Remember from earlier though, word count is easily biased by bigger documents, so maybe a more normalised measure like word frequency is better.
We could even use the measures of interesting-ness (TF-IDF) we developed earlier to moderate these probabilities ... that way we de-emphasise words like "the" and "a" which will dominate co-occurrence. But for now let's keep it simple.
So what can we do with such tables of co-occurrence values?
1. Identify Insightful 2-Word Phrases
We could take the word pairs with the highest co-occurrence value and see if they give us any insight into the corpus. Here's the top 20 for the mini Italian recipes corpus we use for experimenting with: word1 | word2 | co-occurrence | |
|---|---|---|---|
| 0 | of | the | 19.0 |
| 1 | with | a | 17.0 |
| 2 | in | the | 16.0 |
| 3 | a | little | 16.0 |
| 4 | grated | cheese | 16.0 |
| 5 | salt | and | 15.0 |
| 6 | it | is | 14.0 |
| 7 | in | a | 13.0 |
| 8 | them | in | 13.0 |
| 9 | the | fire | 12.0 |
| 10 | and | pepper | 10.0 |
| 11 | and | put | 10.0 |
| 12 | on | the | 10.0 |
| 13 | they | are | 10.0 |
| 14 | oil | and | 9.0 |
| 15 | to | be | 9.0 |
| 16 | over | the | 9.0 |
| 17 | tomato | sauce | 8.0 |
| 18 | with | the | 8.0 |
| 19 | butter | and | 8.0 |
This is just like taking the top 20 n-grams by word count that we did before. That's ok - remember we're doing it this way because this way can be extended to new ideas .. hang in there!
We can see that only a few of the top 20 word pairs are actually that insightful ... most of the words are what we previously called stop word - boring and not unique. We'll try applying the uniqueness factor later.
If we didn't know what a corpus was about, bringing out the top 20 2-grams like this helps us understand that it might be about food or recipes.
2. Generate sentences!
This is going to be fun.Imagine we pick a word at random .. we can use that table to look up the most likely next word. We're going from word1 to word2. Fine, nothing special here.
But if we then take that second word, and use it as the first word, we can find the most likely next word .. a third word. If we repeat this, we ca get a whole sequence of words.
Maybe we'll get meaningful sentences? Let's try a few ... the following shows sequences of 7 words (we could do more, or less) with deliberately chosen first words.
the fire with a little more and pepper
once into the fire with a little more
then cut them in the fire with a
olive oil and pepper and pepper and pepper
tomato sauce salsa bianca this sauce salsa bianca
cut them in the fire with a little
cook in the fire with a little more
little more and pepper and pepper and pepper
So for a first go ... that's kinda spookily good! Some of the sentence seem to be fairly well formed, and actually very much on topic!
Because we're not doing anything more sophisticated (we could) we do fall into traps like word sequences that keep repeating like "olive oil and pepper and pepper and pepper".
Phrases like "cook in the fire with a little more" are pretty impressively natural!
We should be really pleased with this - a super simple technique - and we get spookily good results!
3. Graphs of Word Nodes Linked by Co-occurence
This is also kinda cool .. and open up lots of possibilities that we'll explore later.If we take the word pairs with the highest co-occurrence values, and plot them as connected nodes, the resulting graphs can be interesting, beautiful, and hopefully insightful too ... because we can see which words are connected which other words, and whether some words are the nexus of many others .. and in some way central to the meaning of the corpus.
Let's try it with the small Italian Recipes corpus. We developed force directed graphs in the last post and they've been improved to have word labels, colours, and also wider links for larger co-occurrence values ... click on the following to enlarge it.
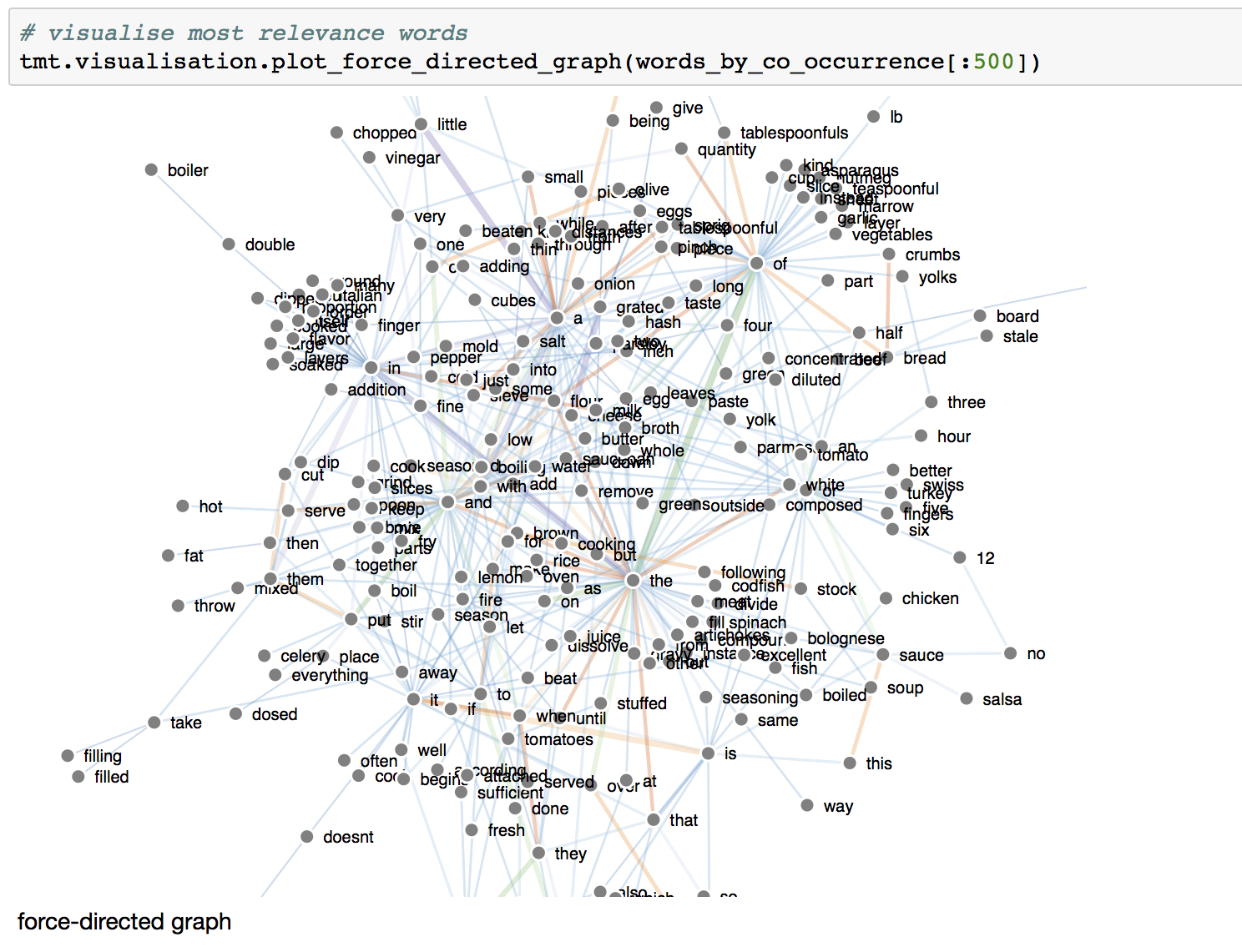
Well .. it's busy! It's the top 500 word pairs by co-occurrence value. You can also see that there is some structure .. with some words clustered around what must be important words. Either drag a node, or hover over it, to see what the word is.
As we half-expected, many of the central words are actually those stop-words .. those boring words that aren't that insightful. The words "in", "of", "the" are at the centre of quite a few clusters. That's ok - we're just starting to explore using graphs .. we can find ways of removing or reducing them, be using stop-word exclusion lists or using the TF-IDF measure of interesting-ness we developed earlier.
Before we do that - have a look at just the following graph which only shows those pairs which have a co-occurrence above 3 .. in an attempt to remove noise and concentrate on those pairs for which there is lots of evidence for that pairing.

That's much clearer if we're busy and don't have time to explore a graph of loads of nodes.
Code
As usual the code for both the data processing pipeline is in a notebook on github:And the code for the visualisation is also on github, the following sows the library function and the d3 javascript:
- https://github.com/makeyourowntextminingtoolkit/makeyourowntextminingtoolkit/blob/master/text_mining_toolkit/visualisation.py
- https://github.com/makeyourowntextminingtoolkit/makeyourowntextminingtoolkit/blob/master/text_mining_toolkit/html_templates/d3_force_directed_graph.js
Next Ideas
This is a great start ... and we've developed a powerful (and pretty) visualisation too! Here are some of the ideas we can try next:- Use stop-word removal or TF-IDF measures to reduce importance of boring words.
- Extend co-occurence beyond just two words .. maybe 3, 4 or even much longer sequences ... suitably adjusted so that closer words are still given a higher score. This will deal with language which often places important words around a boring word like "apple and pear" ... "fish in the oven" ...
No comments:
Post a Comment